
In this document, we discuss about guidelines for end-to-end encryption, in a web environment, in order to ensure the user privacy by making the server blind on the encrypted data. We also provide a performance benchmark to evaluate the encryption impact, depending on the user device and data size.
Introduction
End-to-end encryption, as quoted from Wikipedia, is:
a system of communication where only the communicating users can read the messages
For instance, Signal and ProtonMail both use end-to-end encryption, where the end refers to users: this guarantees that nobody but the communicating users can read the exchanged data.
This is also sometimes refered as client-side encryption, as opposed to server-side encryption, notably because the "end-to-end" terminology is sometimes misleadingly used, when the end is actually the server. In this case, the data is encrypted between the client and the server, but can be decrypted by the latter.
In this document, the end refers to the users' devices: the goal is to encrypt data from applications in such a way that the server cannot decrypt it. But to avoid any confusion, we will use the "client-side encryption" terminology in the following.
These generic guidelines were made in the Personal Cloud context, where the user, let's call her Alice, trusts the server to correctly manage her data and deliver the expected service. But she does not grant it unconditional trust, especially for private data, such as private pictures, confidential documents, passwords, etc. Indeed, Alice knows that even though a service provider follows security good practices and seems reliable about user privacy, any server can be breached and user data leaked.
Therefore, we assume a threat model where the server is semi-trusted, in the sense that it will honestly run the service and won’t try to deviate from expected computations, but might, however, access information from legitimate exchanges. Note this threat model is known in the litterature as honest-but-curious (see Definition 1 in this paper).
⚠️ This does not mean that the server is intentionally curious about user data. For instance, Cozy Cloud is very cautious about privacy and does not leak any user data. However, as stated before, any server can be breached: hence, we seek to reduce the data exposition on the server side to its bare minimum. Also, it is worth noticing that any hosting provider can actually run a Cozy server, as the code is open-source. The trust granted to the hosting provider can vary and one might want to keep sensitive data out of server sight: end-to-end encryption can help to achieve this.
In this document, we propose a complete end-to-end encryption scheme, from user authentication to the retrieval of the encrypted data. We particulary focus on usability and feasibility, as we believe that this is crucial for the overall adoption of encryption ; security and more particularly encryption is often purely grasped on the technical side with few or no consideration for user experience.
As a result, we did not pursued the best theoretical encryption protocols, but rather preferred to make pragmatic choices, by using state-of-the-art security in real-world attacks scenarios that would cope with our threat model.
We do not make any assumption on the type of data to encrypt, which could be pictures, text files, passwords, etc. However, some performances issues could be raised depending on the data size: we therefore made a benchmark in an open-source file management application named Cozy Drive, giving some insights on the actual encryption impact depending on the file size.
Finally, it is worth saying that rather than reinventing the wheel and making up our own encryption system, which is always a bad idea in cryptology, we took inspiration from existing well-proven solutions using client-side encryption, notably passwords manager, such as 1Password, LastPass or Bitwarden, storage systems, like Tresorit, or email services like ProtonMail.
⚠️ This document was written in the first semester of 2020 and reflects knowledge from this period. Some sections might become out-of-date, depending on implementations evolution, state-of-the-art progress, etc.
Baseline
- P : the user password
- Km : the master key deriving from the user password.
- Hauth : the authentication hash, computed from the user password.
- Kvault : an AES encryption key randomly generated. It is encrypted by Km and used to encrypt all others encryption keys.
- Kaes-i : an AES encryption key, randomly generated. It is encrypted by Kvault and used to encrypt user data.
- ivi : initialization vector, used to make the encryption non-deterministic. It means the same plaintext won’t produce the same cipher.
ℹ️ The user password is the root of security. While it has some known drawbacks (it can be forgotten, stolen, brute-forced, etc), this is nowadays the main authentication method that any user knows. There are already many resources for guidelines on the password generation and best practices, like the one from the NIST. Complementary, it is highly recommended to enable two-factor authentication.
ℹ️ Keys and IV generation must be properly done to guarantee the robustness of the encryption. See the NIST recommendations for key generation and the IETF memo for the initialization vector.
❓ Why both Kvault and Km
It is because of revocation: if only Km were used, a password change would force the re-encryption of all the AES keys, which can be a heavy process if a lot a documents are encrypted. This indirection allows to just revoke Km and re-encrypt Kvault after a password change.
Authentication
As the password is used to compute Km, the encryption master key, it should never be sent in clear to the server.
The authentication flow is represented by this schema:
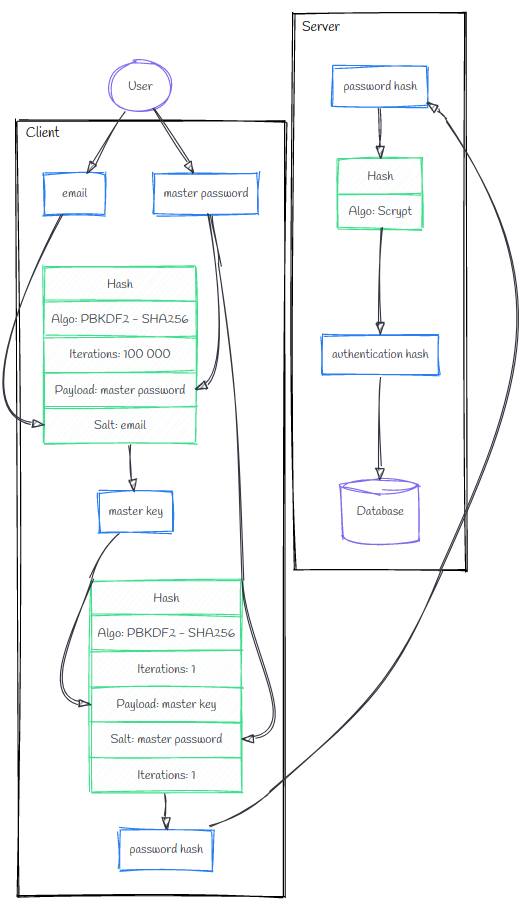
Once the user entered her password, it is hashed through a key derivation algorithm, by using the user email as a salt. The generated output is Km.
Then, Km is itself hashed with the password as salt to generate the final password hash. This hash is sent to the server, which computes a new hash based on it to produce Hauth, the authentication hash. If it matches the one stored in database, the server grants access to the user.
With this protocol, the server learns nothing about the user password.
ℹ️ This authentication protocol is heavily inspired from Bitwarden and an implementation has been made in Cozy.
ℹ️ The key derivation algorithm on the client side is PBKDF2. We chose it over more modern algorithms such as scrypt, bcrypt or argon2 as it is a well-known algorithm, largely used and tested, and natively supported in modern browsers, through the SubtleCrypto implementation.
On the server-side, we chose scrypt, as it is designed to be more resistant to hardware-specific attacks, such as with ASIC or GPU, by requiring a large amount a memory.
ℹ️ The number of iterations is a tunable choice and a trade-off between robustness to brute-force attacks and speed. 100 000 is the value used by 1Password and LastPass.
ℹ️ The email is used as a salt, which is also the choice made by the password manager Bitwarden. Any persistent user data could be used, if it is long enough to ensure uniqueness, i.e. not a name or postal code for instance. In our implementation, this email is automatically built from the user domain.
Encryption
Key vault creation
The encryption process starts by generating Kvault, the vault key, that will be used to encrypt future AES keys.
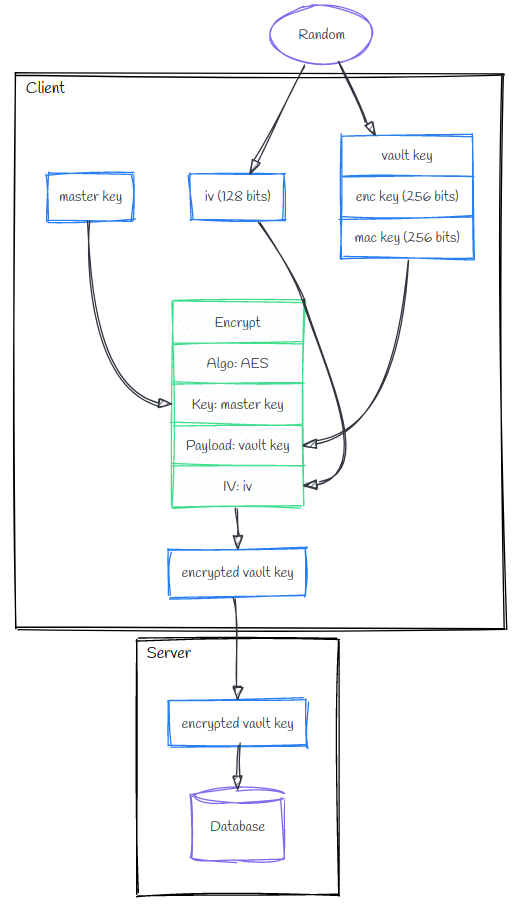
Encryption
Kvault is itself an AES key, encrypted with the master key Km. It is stored in the database and retrieved and decrypted once the user is connected. It can then be used to encrypt data:
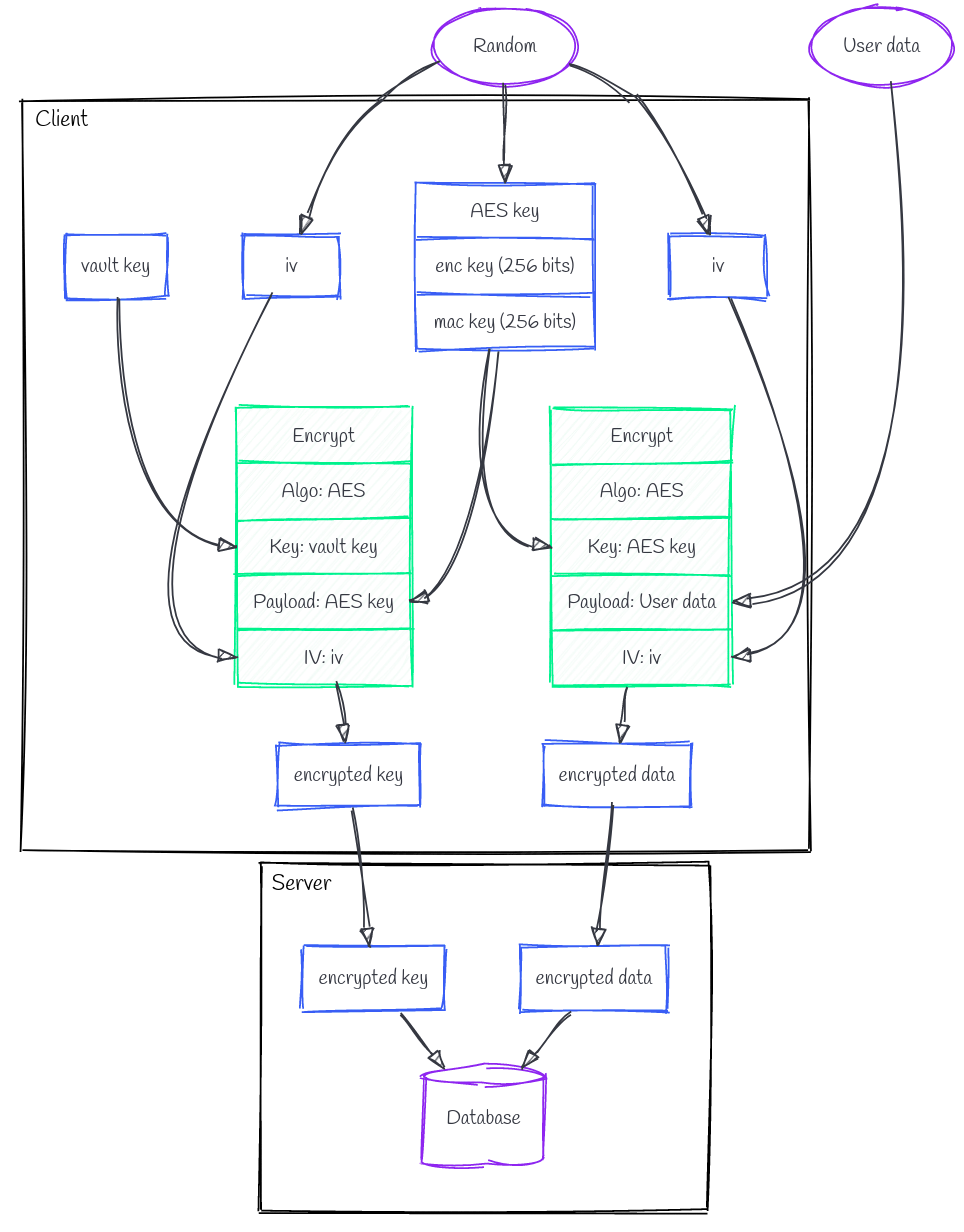
Each user data is encrypted with a dedicated AES key, Kaes-i, itself encrypted with Kvault. Note the iv must be always different to make the encryption non-deterministic.
Decryption
When the user wants to decrypt data, the following steps are made:
- The user enters her password
- Km is computed
- Kvault is retrieved and decrypted by Km
- The data i is retrieved with its associated key Kaes-i
- Kaes-i is decrypted with Kvault
- The data i is decrypted with Kaes-i
ℹ️ Steps 1 to 3 only occurs once during a session. Kvault is kept in memory so the user doesn’t have to enter her password every time she needs to encrypt/decrypt.
ℹ️ For each decryption step, the iv used to encrypt is retrieved. It can be stored alongside the encrypted data and does not require specific protection.
Key reuse
Kvault could be used to encrypt/decrypt any data, as long as a different iv is used every time. However, this might introduce vulnerabilities in some encryption schemes.
To illustrate this, let us assume A and B are encrypted with the same key K (this is a simplification; the actual AES mechanisms are actually more complex than this example) :
A ⊕ K = A'
A ⊕ K = B'
A'⊕ B' = (A ⊕ K ⊕ B ⊕ K) = (A ⊕ B) + (K ⊕ K) = A ⊕ B
Thus, if the attacker is able to know some bits from A, it will be able to gain information on B.
This being said, if we assume that K = Kaes-i ⊕ ivi, K will never be the same for two different encryption round as the ivi is always different, making our example above impossible in practice as there actually will be a K and K', making it impossible to gain any information between A et B. However, it is considered as a good practice to use a different key for a different data as it can still protect the encryption if the ivi generation is compromised which could happen for random generation for instance.
In the same manner, if data is updated, for instance, a picture, Kaes-i should be revoked and another key Kaes-i generated to re-encrypt the picture with a new ivi.
Data sharing
Using a different Kaes-i for each data type also eases data sharing: if one Kvault were used to encrypt everything, a sharing would either imply to share Kvault, or to re-encrypt each data to share with recipients’ public keys.
The former would not be acceptable for security while the latter is not very efficient: asymmetric encryption is quite low compared to symmetric encryption and would cause significant performance issues for sharing many and/or huge files. Moreover, any update to the shared data would require to re-encrypt with the public keys.
The use of Kaes-i keys allows to simply share the data key to the recipients’, encrypted with their public keys. Recipients are thus able to decrypt the Kaes-i with their private key, re-encrypt it with their own Kvault and to store it alongside the shared data.
Key storage
The encryption keys should never be stored insecurely on the user device, i.e. decrypted with no protection whatsoever. Otherwise, it would mean a compromised device would be able to decrypt any data.
On mobile, it is possible to use the Apple’s keychain or Android’s keystore.
On a desktop environment, the hard drive can be encrypted at the OS level, or to the hardware-level, such as with Intel SGX enclaves, where the key would be securely encrypted by a key directly stored in the CPU.
In the browser, there is unfortunately no easy way at this moment to securely store encryption keys ; therefore we strongly discourage storing plaintext keys in the browser.
Technical guidelines
In this section, we provide guidelines for the implementation of client-side encryption and detail some of the technical choices we made.
We considered a full JavaScript environment, as it can be executed natively in the browser, but also in mobile environment through frameworks like Cordova, or in desktop, with Electron.
We rely on the WebCrypto API specifications as it is a recommended standard by the W3C, has been audited by the community and is natively supported by the majority of modern browser through the SubtleCrypto interface.
- W3C recommendation: https://www.w3.org/TR/WebCryptoAPI/
- Documentation: https://developer.mozilla.org/en-US/docs/Web/API/Web_Crypto_API
- SubtleCrypto: https://developer.mozilla.org/en-US/docs/Web/API/SubtleCrypto
- Audit: https://hal.inria.fr/hal-01426852/document
Although this API is quite recent, it is notably used by:
ℹ️ The WebCrypto API is available on browser and mobile (e.g. with Cordova), on which we performed tests. However, the desktop environment requires Node.js Javascript, which does not implement the SubtleCrypto interface. An alternative is natively supported, and it is possible to use a polyfill version, although it is experimental and not recommended yet.
In the following, the terms generate, derive, wrap, unwrap, encrypt, decrypt refer to their implementation equivalent.
The symmetric encryption algorithm used is AES-GCM that allows:
- Robust encryption
- Data integrity, thanks to a Gallois Message Authentication Code (GMAC)
- Attach arbitrary plaintext metadata
The encryption used to store encryption keys is AES-KW: it is specifically designed for this task, called wrapping (unwrapping for the reverse) and allows, just like AES-GCM, to ensure the encryption integrity.
One benefit from AES-KW is that there is no need for iv to produce non-deterministic encryption, because it is internally handled in the algorithm specification.
ℹ️ If not specifically mentioned, performances measures were made on a Thinkpad T480, with a i7-8550U CPU, 16Go of RAM and a SSD. The browser was Mozilla Firefox 70.0.
Each given measure is the mean of 1 000 same computations.
Key derivation
To derive strong keys from a password and a salt, e.g. Km, we use SubtleCrypto.deriveKey()with the following parameters:
algorithm; an object specifying the derivation algorithm, here aPbkdf2Paramswith the following attributes:name = PBKDF2salt = emailiterations = 100 000hash = SHA-256
baseKey =P: the derivation input, here the user passwordderivedKeyAlgorithm={name: "AES-KW"}: the encryption algorithm of the derived keyextractable =false; indicates that the key won’t be later exportedkeyUsages = ["wrapKey", "unwrapKey"]; the authorized operations for this key.
Performances
The key derivation performance is linear to the number of iterations, as shown in this figure:
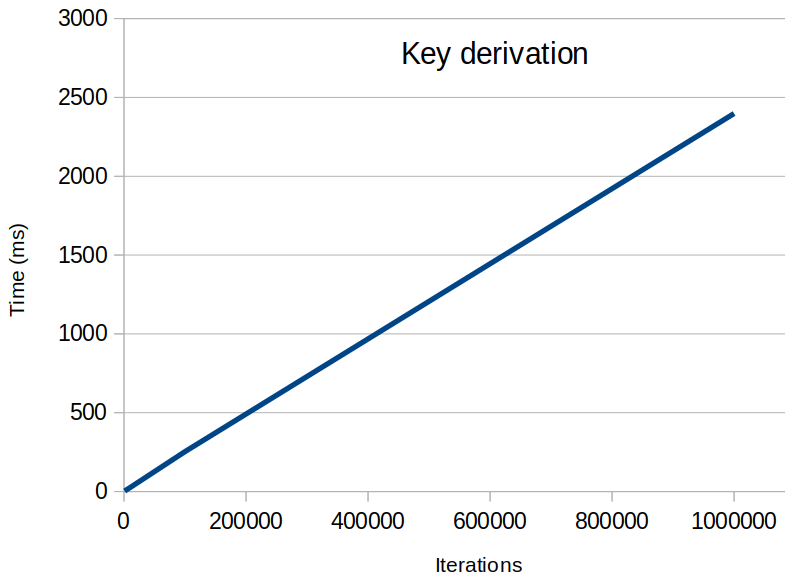
See also the table below, for more precise values:
| Iterations | 1 000 | 10 000 | 100 000 | 1 000 000 |
|---|---|---|---|---|
| Time (ms) | 3 | 25 | 253 | 2398 |
The number of iterations is crucial for the security: the higher the better, as it will force an attacker to perform more operations and thus slow down an attack.
100 000 iterations seem a good compromise between security and performance. It also shouldn’t be forgotten that we performed tests on a modern computer, while some users might have older hardware, leading to degraded performances that could be prohibitive for user experience.
See this post for more insights on the iterations choice.
Key generation
To generate the symmetric keys, e.g. Kvault, Kaes-i, we use SubtleCrypto.generateKey() with the following parameters:
algorithm = {name: "AES-GCM", length: 256}; the encryption algorithm and the key lengthextractable = true; indicates that the key will be later exportedkeyUsages = ["encrypt", "decrypt", "wrapKey", "unwrapKey"]; the authorized operations for this key. Typically, a Kaes-i will have["encrypt", "decrypt"]while Kvault will be used to wrap/unwrap Kaes-i, thus["wrapKey", "unwrapKey"]
Performances
The key generation operation, as well as wrapping and unwrapping, are not critical on a performance level, as shown below:
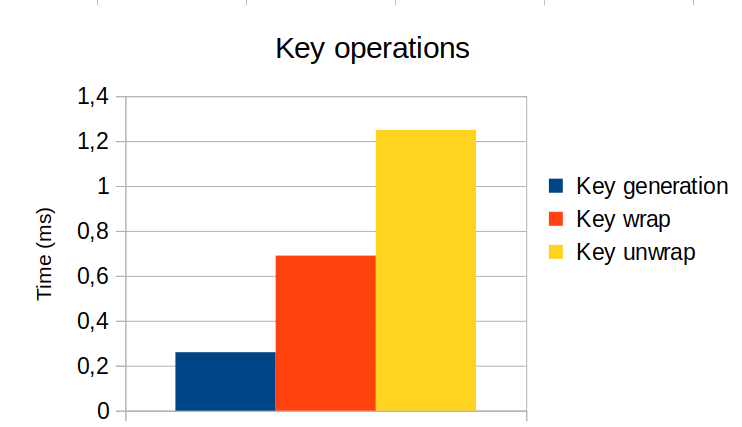
The operations do not exceed 1.2 ms, which is beneath the human perception.
Key wrapping
To wrap an encryption key, i.e. encrypt and serialize it in specified format, we use SubtleCrypto.wrapKey() with the following parameters:
format = "raw"; the exported formatkey; the key to export, e.g. Kaes-iwrappingKey; the export key, e.g. KvaultwrapAlgo = "AES-KW"; the encryption wrapping algorithm
Key unwrapping
To unwrap a wrapped key, i.e. decrypt and deserialize it in specified format, we use SubtleCrypto.unwrapKey() with the following parameters:
format = "raw"; the expected key formatwrappedKey; the encrypted key, e.g. Kaes-iunwrappingKey; the key used to wrap, e.g. KvaultwrapAlgo = "AES-KW"; the encryption wrapping algorithmunwrappedKeyAlgo = {name: "AES-GCM", length: 256}; the expected imported key format. If thewrappedKeyis Kvault, it will be{name:"AES-KW"}extractable = true; the key can be re-exported laterkeyUsages = ["encrypt", "decrypt", "wrapKey", "unwrapKey"]; the authorized operations on the imported key. Typically, a Kaes-i will have["encrypt", "decrypt"]while Kvault will be used to wrap/unwrap Kaes-i, thus["wrapKey", "unwrapKey"]
Data decryption
To decrypt data, we use SubtleCrypto.decrypt() with the following parameters:
algorithm; an object specifying the algorithm to decrypt. We useAesGcmParamswith the following properties:name ="AES-GCM"; the encryption algorithmiv; the initialization vector randomly chosen at the time of encryption. It should be retrieved alongside the encrypted data. WithAES-GCM, a 96 bits iv is recommended. See the NIST recommendations.tagLength = 128; the expected GMAC length. See the NIST recommendations for insights on the GMAC length.
key; the encryption keydata; the data to decrypt
ℹ️ The data must be represented as a BufferSource object.
Performances
The decryption has roughly the same performances than the encryption, discussed in the next section.
Data encryption
To encrypt data, we use SubtleCrypto.encrypt() with the following parameters:
algorithm; an object specifying the algorithm to encrypt. We useAesGcmParamswith the following properties:name ="AES-GCM"; the encryption typeiv; the initialization vector randomly generated at the time of encryption. It should be stored alongside the encrypted data. WithAES-GCM, a 96 bits iv is recommended. See the NIST recommendations.tagLength = 128; the GMAC length. See the NIST recommendations for insights on the GMAC length.
key; the encryption keydata; the data to encrypt
ℹ️ The data must be represented as a BufferSource object.
Encryption performances
In addition, we performed a benchmark of data encryption. To do so, we implemented encryption methods in Cozy Drive, a pure client-side file management app, written in JavaScript and React, which can be run in a browser and in a mobile environment, through a Cordova wrapper, using a WebView. Our implementation uses the WebCrypto API with the methods and parameters described above.
We focused on file encryption, as it is probably the most common data type from the user point-of-view. However, any kind of data can be used with this implementation as the encryption module was separated from the app logic as a web module. All the code is open source and available on Github.
In addition to the encryption cost itself, we also evaluated the read cost as it a necessary step to encrypt the file.
We performed tests in the following environments:
Desktop web browser (Firefox 70.0)
- Thinkpad T480 (i7-8550U CPU, 16Go RAM)
Mobile app
- iPhone 11 -iOS 13.3 (simulator)
- MacBook Pro (2.3 GHz i5 CPU, 16Go RAM)
- Webview: UIWebView
- iPhone X - iOS 13.3
Webview: UIWebView
- Xiaomi Mi 9 - Android 9
- Webview: Chrome 80.0
ℹ️ All the Y-axis are in logarithmic scale.
Firefox 70.0
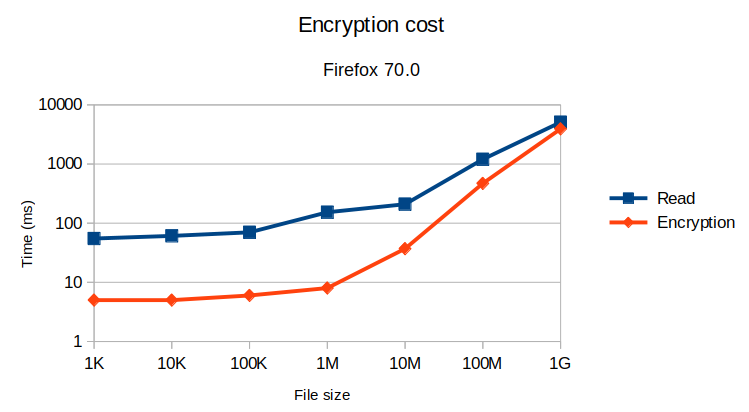
This represents the measures taken in the Firefox browser on a laptop.
As we can see, the encryption cost is always lower than the read time, and is quite low as long as the file size is small.
However, we can notice an acceleration of the cost starting from 1 MB. Before this limit, the encryption cost is almost free, less than 20 ms, and jumps to more than 100 ms for 10 MB.
Interestingly, this acceleration seems to coincide with the file chunk size of the FileReader API: we can then make the assumption that this overhead could be caused by the split of the file in smaller chunks.
However, despite this acceleration, the cost is sub-linear to the file size. This is good news, but still can lead to a significant cost for large file: a 1 GB file upload will take ~10 s to be read and ~9 s to be encrypted, so almost 20 s in total.
Now, let’s see the performances on mobile.
iOS 13.3 - Simulator iPhone 11
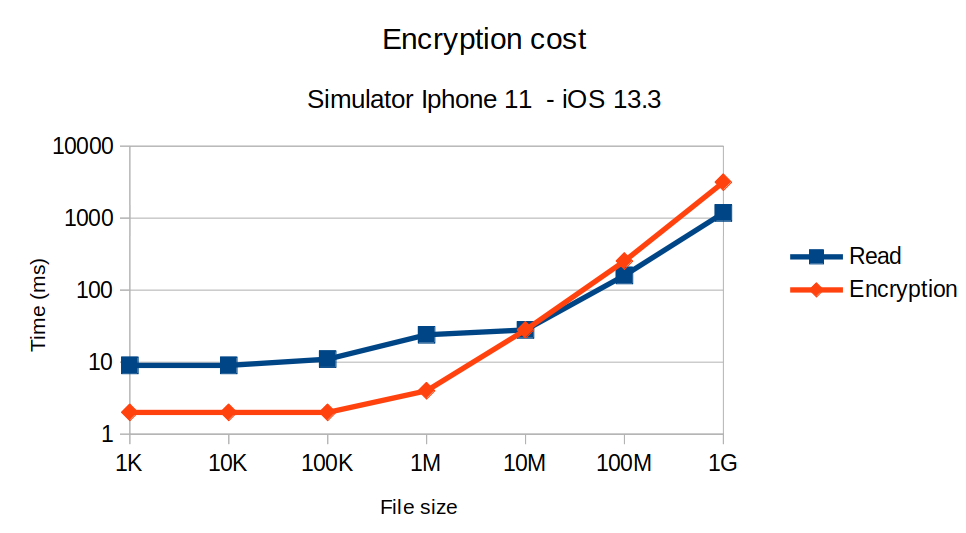
We performed this test in the iPhone 11 simulator provided by Apple. We can see the overall performances are better than in the browser. And similarly, the cost tends to increase when the file is larger than 1 MB, especially for encryption. The read operation being relatively stable up to 10 MB.
However, this evaluation can be biased by using a simulator, which might not simulate exactly the mobile hardware, especially the CPU. Therefore, we also took measurements in real devices.
iOS 13.3 - iPhone X
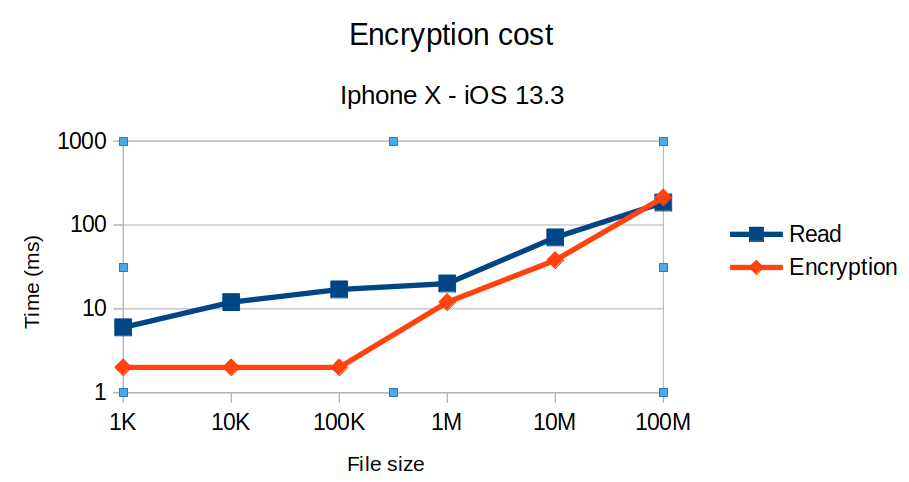
The shape of the performances looks actually quite similar than the simulator. Note there is no measure for a 1 GB file, as it took too much memory for the device to handle. It might be interesting to design strategies to deal with large files, like splitting the file in chunks and encrypt each part separately, or to perform an encryption stream. See the next section for more insights.
Android 9 - Xiaomi Mi 9
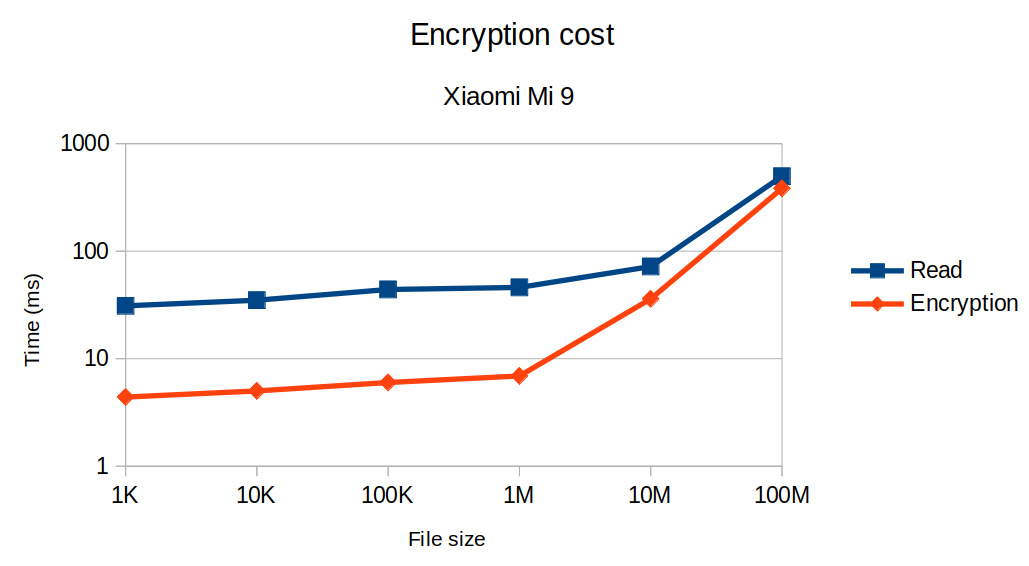
On an Android Device, the overall performances were a bit behind the iPhone, especially for the read, which might be explained by the hardware differences.
However, it is worth noticing that the encryption cost is almost the same from 1 K to 1 MB. The acceleration occurs at 10 MB.
Performances by devices
Here, we group the performances for all devices, to emphasize the environments differences.
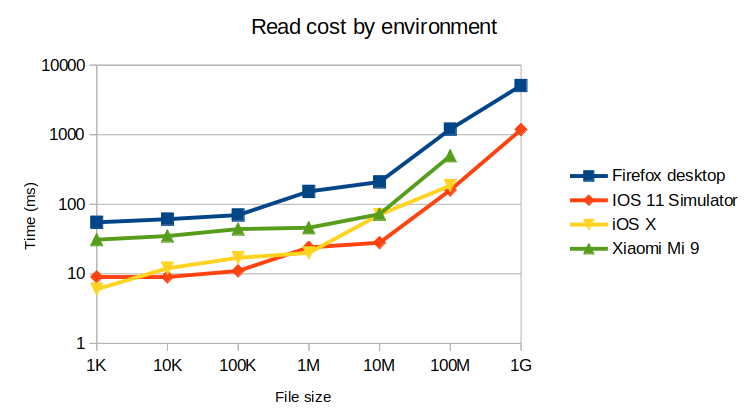
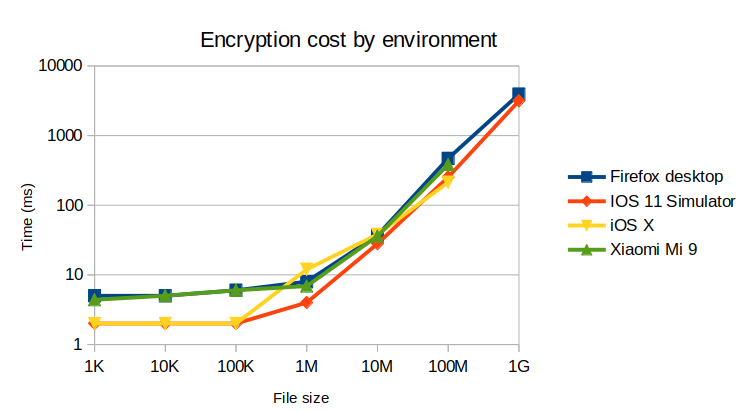
Surprisingly, the Firefox desktop performs poorly for the read operation compared to the mobile environments. We also notice that iOS performs quite well on small files, but all environments converges to similar performances on huge files, especially for encryption.
Performances findings
The performance benchmark stressed the fact that the encryption cost is almost insignificant for data up to 1 MB. Consequently, a client-side encryption is nowadays realistic, even in the browser, as long as the data size is kept reasonable.
As the file size grows, the encryption tends to perform with the same cost than the read operation, which can be substantial for large files. Then, it becomes necessary to investigate new strategies to efficiently cope with this cost without degrading the user experience.
Web workers
In our implementation, we explored the possibility to use a web worker. This recent technology, available in modern browsers, gives the possibility to run tasks in background threads. This is particularly useful for computational heavy tasks that would block the main thread, and give the user a freezing interface.
We implemented the encryption in a web worker with no impact on the task itself. However, an additional cost was added to actually execute the worker.
It is also worth noticing that a web worker does not share memory, as specified in the documentation:
Data passed between the main page and workers is copied, not shared. Objects are serialized as they're handed to the worker, and subsequently, de-serialized on the other end. The page and worker do not share the same instance, so the end result is that a duplicate is created on each end. Most browsers implement this feature as structured cloning.
Therefore, one should perform the whole data upload in a web worker, rather than reading the data in the main thread, copy the data to the worker and perform encryption, which can be very memory-consuming for large files.
A good implementation example for this is Firefox Send.
File streaming
The WebCrypto API only allows encryption/decryption by block; it means the data must be entirely loaded before performing the operation.
It would be much more efficient to stream the data in case of huge files to avoid having to load it entirely in memory once, which can cause memory failure as we experienced in our tests on mobile.
Unfortunately, this is not natively supported by the WebCrypto API for now. An issue has been opened on this matter and was still discussed at the redaction of this document.
Note it is still possible to manually implement this streaming, like Mozilla did for its Send service but it requires additional work.
Conclusion & perspectives
Client-side encryption becomes progressively mainstream, through messaging apps, email services, passwords manager, file storage, etc.
However, despite its clear benefits for user privacy, it is still largely underused.
One common criticism is the impact of performances, that, as we shown in this document, remain relatively low as long as data size is kept reasonable. Web workers and file splitting both seem good candidates to soften this cost and are not mutually exclusive.
Also, the rise of WebCrypto API has significantly eased the developer task, providing a simple API to encrypt/decrypt data. However, the actual use of this API is not straightforward to make the correct choices. We hope this document provides comprehensive insights to anyone that would be interested to implement client-side encryption and authentication, while still keeping in mind that encryption must not be tackled lightly. As quoted from the WebCrypto homepage:
If you're not sure what you are doing, you probably shouldn't be using this API.
There are still many challenges to address in the area of client-side encryption: we list some of them below with future perspectives.
Improved authentication security
The main drawback of our authentication method is the necessity to transmit a hash derived from the password to the server side. Even though it supposedly reveals nothing on the password, it can still be stolen to be cracked later thanks to powerful hardware and dictionary attack.
The SRP protocol is a zero-knowledge protocol which doesn’t require to derive a secret from the password and reveals nothing to a compromised server or to an attacker able to compromise the TLS connection and perform a man-in-the-middle attack. This protocol is claimed to be used by 1Password and ProtonMail, but is more complex and arguably slower than the authentication scheme described above.
ℹ️ There exists an open-source Javascript implementation made by Mozilla, claimed to be used in production in their identity protocol. See node-srp.
Untrustful server
In a web context, the server dynamically delivers the scripts run by the browser. The server is then assumed to be trustful to deliver the correct code.
However, a deceptive server might deliver corrupted script to intercept the user password and be able to decrypt its data, as mentioned in a security analysis of ProtonMail.
We did not considered this kind of attack in our threat model, as it goes beyond the “honest-but-curious” postulate, but we mention it for exhaustiveness.
A way to tackle this issue is the use of the SRI security feature, available in browsers and now used by ProtonMail: the server providing the HTML must give a hash of the script, that will be computed by the browser to ensure its integrity. If the values mismatch, it might indicate that the server did not deliver the expected resource: the script is therefore blocked.
Nevertheless, it is not enough if the server delivering the script is the same as the one delivering the HTML: the hash can then be the one of the corrupted Javascript.
But if the service provider publishes the script in open-source, with the expected hash, anyone can check if the server delivers the expected code. Though it is not really satisfying, as it requires manual action from users, it adds some control on the content delivered from the server.
Server-side computation
A serious drawback when doing client-side encryption is the loss of server-side computation ability. As the data is encrypted, the server becomes incapable of performing treatments on it, such as indexing, AI computations, search, etc.
There is no generic solution to overcome this issue which depends on many variables and requires to find compromise on the encryption surface, performances, protocol complexity, etc.
For instance, it is possible to keep indexed data in clear, e.g. the file hierarchy structure, the creation date, etc, but to the cost of potentially weaken user privacy.
It is also possible to encrypt indexes and perform queries on the client-side, with browser database like PouchDB, but this at the cost of performances and scalability.
Another approach consists of encrypting data on the client in a deterministic way, so that an encrypted term, e.g. a directory ID, can be indexed and retrieved. The drawback here is the risk for frequency-based attacks, with an attacker observing queries timing and their result to infer information.
More sophisticated solutions involve homomorphic encryption which allow to perform treatment directly on encrypted data, without requiring to decrypt it at anytime. This is still an active topic of research but, at this moment, seem too computational heavy and context-specific to be a practical solution: an AES128 block takes about 4 minutes to be evaluated in best scenarios and any homomorphic treatment requires specific and complex design that must be carefully analysed.
Loss of user password
In the proposed encryption scheme, the root of security is the user password. Therefore, if the user loses her password, there is no way to recover the encrypted data, as the server must never know the encryption key. This is a risk assumed by security-oriented product such as passwords manager, but this might be unacceptable in other contexts.
An elegant solution to recover encrypted data after a password loss is the use of Shamir’ secret sharing. The principle is the following:
- The user choses a number of trusted recipients, e.g. 5, and a quorum, e.g. 3.
- The user secret, here, the master key, is splitted in as many shares as trusted recipients.
- The user distributes the shares to the trusted recipients, through a secure channel.
- If the user loses her password, she contacts her trusted recipients to get their respective shares. She only needs to retrieve a number of shares equal to the quorum to recover the secret.
While simple, this protocol raises many issues, notably the user experience, the recipients discovery, the trust granted to the recipients, the shares sustainability, etc.
Acknowledgment
This project has received funding from the European Union’s Horizon 2020 research and innovation programme under the NGI_TRUST grant agreement no 825618.
![]()
![]()
Readings, links et resources
More about encryption in Cozy with our Data Scientist, Paul Tran-Van
More details about encryption in Cozy available on our Github page



