
Introduction
Cozy is a versatile open-source personal cloud used to gather your personal data in a safe place. You can develop any client-side application to manipulate existing data types, called doctypes, or simply create your own.
As a result, many types of data can be stored in a single database instance. It is then crucial to be able to efficiently query data so the user can smoothly retrieve it.
Over the years, we witnessed many different use-cases of data manipulation at Cozy Cloud and gained some experience about scalability issues and common traps developers might fall in when dealing with databases.
This article aims to give a short overview of the most common mistakes we saw (and - let’s admit it - sometimes made!) about data indexing and querying. The concepts we discuss here are rather generic and can be applied to many database engines, both SQL and No-SQL. In the following, our examples primarily assume a CouchDB database, as this is the one used in Cozy, but we provide pointers to the equivalent concepts for PostgreSQL and MongoDB, which are some of the best known database engines, respectively in SQL and document-oriented No-SQL.
Our example uses cozy-client, a Javascript library that provides an API to simplify the interaction with the Cozy backend, for authentication, realtime, offline, etc. And most importantly, it provides interfaces to query the database and deal with the indexes.
Indexes: the what and the why
Index: why?
Indexing data is useful as soon as your database grows and data cannot be retrieved in a reasonable time through full-scan queries, i.e. by scanning the whole database.
Most of the time, you don’t want to query all you data at once: you use filters to restrict the selected data. It is typically done through a where clause in SQL, a find method in MongoDB or a selector in CouchDB.
You might also want to retrieve data in a particular order, by sorting it, or selecting only certain fields to be returned.
While it is possible to do such tasks on the client side, they are generally delegated to the database server to ensure scalability. After all this is its job!
However, there is no magic here: you cannot expect a database to automatically deal with large amount of data in a perfectly suitable way for your needs.
This is where indexes takes place: they are used to tell the database how to organize data in such a way that your queries can be efficiently run, even though the database contains millions of elements.
ℹ️ Index is obvisouly not the only thing to keep in mind when dealing with databases, but we focus exclusively on it for this article, for the sake of conciseness.
Index: what?
An index is a way to organize documents in order to retrieve them faster.
To give a simple and non-database comparison, a recipe book might have an index listing all the recipes by their name with their page number. If the reader is looking for a particular recipe, this index avoids him to scan the full book to find it.
The principle is the same for database indexes: we want to avoid scanning the whole book (which can be a table, a collection, etc) each time we are looking for specific data: even though computers are way faster than humans to scan data, this task can be very time-consuming when dealing with thousands or millions of documents.
In more formal terms, time complexity of a query run on a database with n documents will be O(n) without index, as it requires to scan all documents sequentially.
There are many types of indexes in the litterature. One of the most common index structure is the B-Tree: it is the default in PostgreSQL, as well as MongoDB. This index structure performs in O(log n) in average, which guarantees a very fast access time even in large
From a practical point of view, B-trees, therefore, guarantee an access time of less than 10 ms even for extremely large datasets.
—Dr. Rudolf Bayer, inventor of the B-tree
In CouchDB, the indexes are actually B+ Trees, a structure derived from the B-Trees.
The indexed data are document fields. When indexed, it is called keys, and are organized as a tree, with the documents stored in the leafs nodes. So, finding a particular document means browsing the tree, from the root to the leaf.
The keys are organized by their value: if we suppose a node with two keys k1 and k2 and three children, the leftmost child node must have all its keys inferior to k1, the righmost child’s keys superior to k2, and the middle child’s keys between k1 and k2.
In the Figure below, borrowed from the CouchDB guide, you see that each node has three keys, but in the CouchDB implementation, a B+ Tree node can actually store more than 1600 keys.
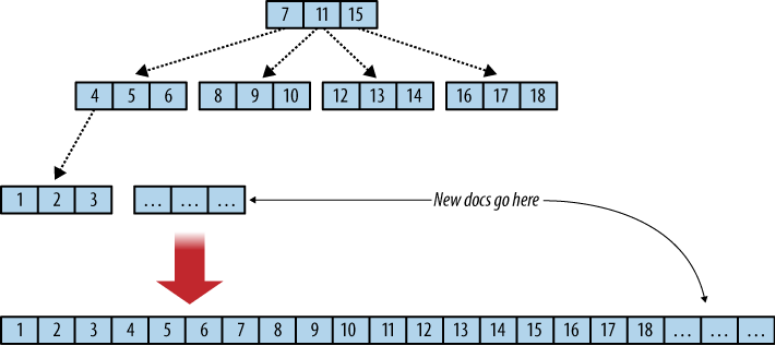
This design is very efficient for range queries: in the example above, a query looking for documents having an indexed field between 1 and 3 will browse the tree to find the first document position (with a key of 1) and then get the next two contiguous documents.
ℹ️ In the following, we refer about “B-Tree”, that can indifferently be applied to B-Tree or B+ Tree: the main concepts remain the same in both cases and their differences are not relevant in this discussion.
Traps with indexes
Indexing data is not as easy as it might look. There is not one way to index, which must depend on you data model and the queries you need to run for your application. But, as you will see in this article, keeping in mind how the indexes - here the B-Tree - work in background helps a lot!
ℹ️ Each database engine has its own way to index data with its own specificities. Therefore, we do not focus on the indexing itself but rather on the common traps that you might encounter when designing indexes for an application, which can be applied to most of the databases, as long as a B-Tree is involved.
Pagination
When there is too much data to handle at once on the client side, it is good to implement pagination. This consists of splitting a Q query into several Qi sub-queries so the client can progressively retrieve data and update the UI accordingly.
ℹ️ From a UX perspective, there are different strategies to implement pagination. Typically if you data is rendered as a list, you can either have a ‘Load more’ button at the bottom or automatically detect the need to fetch more data when the user is at the end of the list.
We focus here on how to split Q and the consequences on the performances.
A simple way to do it consists of combining a limit and skip parameters to the query.
💡 Those parameters are available in CouchDB, as well as MongoDB or PostgreSQL (in SQL, skip is called offset).
Let’s assume Q retrieves 1000 documents. You can implement pagination by running Q 10 times by setting a limit to 100 and skip the number of already retrieved documents.

⚠️ This pagination method does not scale and can be very bad for performances! Let’s see why.
This method actually breaks the B-Tree indexing logic: there is no way to efficiently skip a fixed number of data in such a tree, so skipping documents consists of normally running the Q query and then splitting the results starting from the skip number of documents, until the limit.
Thus, instead of taking benefit from the tree traversal to efficiently start each Qi, the skip forces the query to start each query from the first document of the tree, and perform a sequential scan from there.
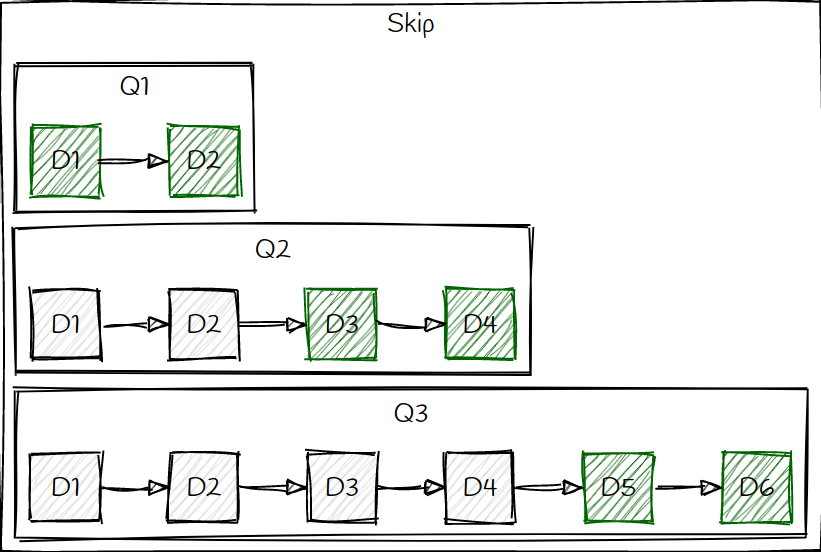
In the schema below are represented the scanned documents for Q1, Q2, Q3, assuming a limit=2 to simplify the drawing.
Q1 needs to scan 2 docs, Q2 4 docs and Q3 6 docs.
The boxes in grey are the documents scanned by Qi and the boxes in green the documents actually returned. We can see that each Qi with i > 1 needs to scan useless documents, this behaviour being worse for each new query.
Fortunately, there are simple and efficient ways to perform pagination.
In CouchDB, you can use bookmarks, that you can see as a tree pointer to indicate where to start the query. This is simply a string returned by each Qi that you can pass as a parameter for the next query:
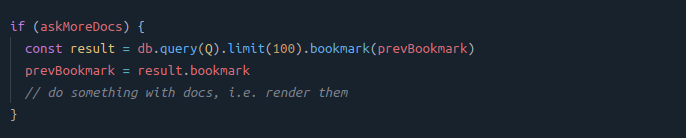
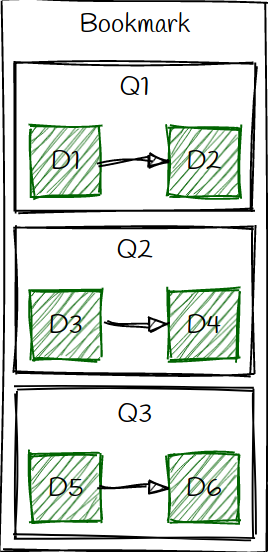
By doing so, each Qi starts at the end of the previous query, avoiding unecessary scan:
💡 This bookmark system does not exist in MongoDB or PostgreSQL. However, you can still benefit from efficient pagination by using the last document key returned by the previous query. As the tree is organized by keys, Qi will be correctly positioned in the tree, that is, at the end of the previous query. See this article for more details about a SQL approach and this article for a MongoDB approach.
Non-contiguous rows
When designing indexes, it might help to keep in mind how the B-Tree are structured, notably when dealing with multi-fields indexes.
Indeed, if you need to query several fields of a same index, you might perform sub-optimal queries if you are not careful.
Let’s take an example to illustrate how such situation could occur. Q is a query for a To-do application that retrieves tasks by their creation date and category, respectively created_at and category.
To do this, you first create an index on those two fields, in this order. Then, you perform a query, for instance to get all the tasks made in 2020 in the "work" category. With cozy-client, this can be expressed like this:
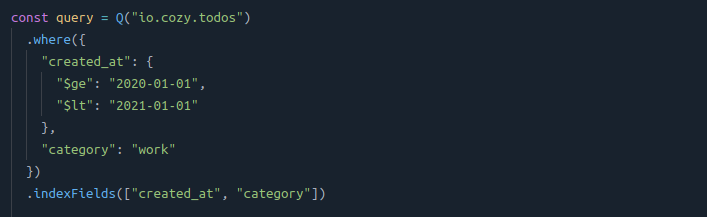
Below is represented a sample of the scanned index data: it starts from 2019-01-01 and stops at 2020-01-01 as the the data is sorted by its first row, the created_at.
Then, for each scanned row of this interval, the entry is returned if it has a "work" category. The returned rows for the query are represented in green.
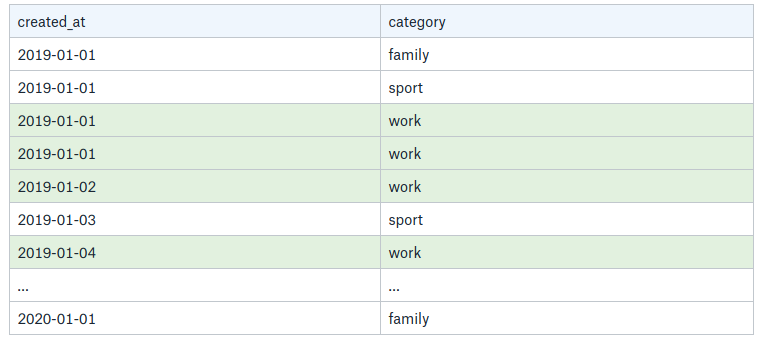
The problem here is that you might scan unnecessary rows: in the example above, you can see a “sport” task made the 2019-01-03. It is not a big deal if the "work” category represents the majority of the tasks, but it is a pity if there are only a few of them. Imagine you have 1000 tasks for this year, with only one being in a "work” category: you’ll have to scan the 1000 tasks to only find one element, so 99.9% of the scanning is actually unnecessary.
In order to make this query efficient, you need to make an index that will organize data in contiguous rows.
Let’s take back our example, but this time by changing the index order: you first index category and then created_at.
The index data is now organized as follow:
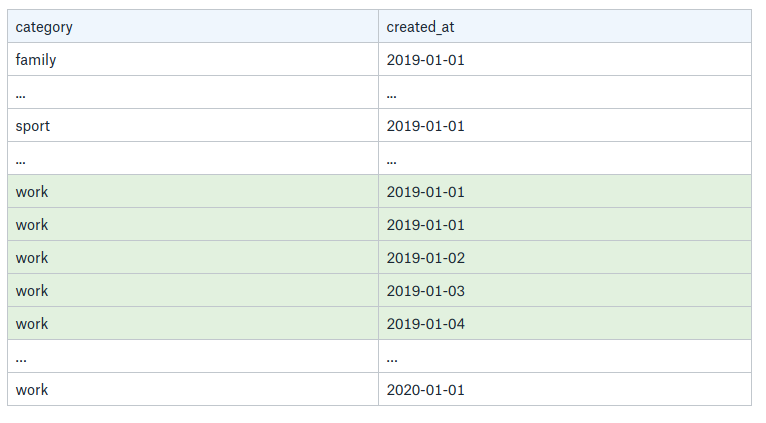
Now, the very same query can be efficiently processed: the "work” category is first evaluated in the B+ Tree, which return all the relevant rows, sorted by created_at. Then, the range is easily found now that all the rows are contiguous and only the returned rows are scanned.
💡 When creating an index, carefully think about how your data will be organized and which query will need to perfom. The performances can dramatically vary depending on your design, with several orders of magnitude.
💡 When dealing with a query with both equality and range, you should first index the equality field. If you are interested about this, you can learn more here for a SQL approach.
However, it is not always possible to keep this design: you might need a more advanced concept called partial index.
Partial index
In the previous section, we saw that a query should be able to be run on contiguous rows in an index to maximize performances. However, this is not always possible when dealing with more complex queries.
We introduce here partial indexes. They are used to express predicates that will be evaluated at the indexing time. Data is then indexed only if it matches the predicates.
This can actually be useful in several situations:
- Queries without contiguous rows
- Queries with existence predicates
- Queries with constant values
Let’s dig in these cases and see how it can be useful!
Queries without contiguous rows
Let us consider a query looking for tasks created after 2019, that are NOT in the “work” category:
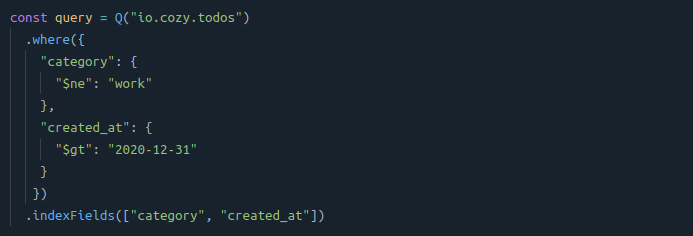
⚠️ The rows cannot be contiguous in the index because of the negative predicate, $neq (for not-equal). The index will have to scan all the rows to find those without the “work” category and filter out the ones without the correct date range.
By using a partial index with the negative predicate, this query becomes efficient as only the tasks without a “work” category will be indexed, by the created_at field.
The query is now:
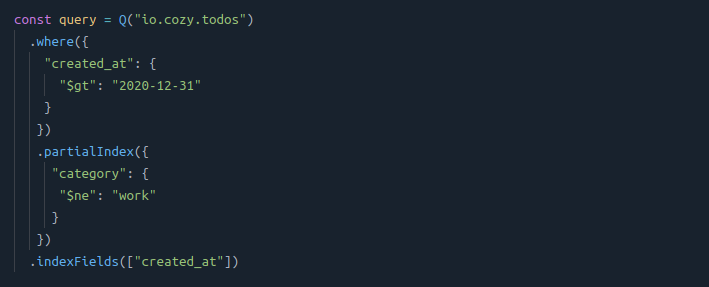
💡 Note it is no longer necessary to index the category field: therefore, the index will be smaller, more efficient and will take less place on disk.
Queries with existence predicates
The category field might be optionnal in your To-do application. In this case, it might be useful to check its existence:
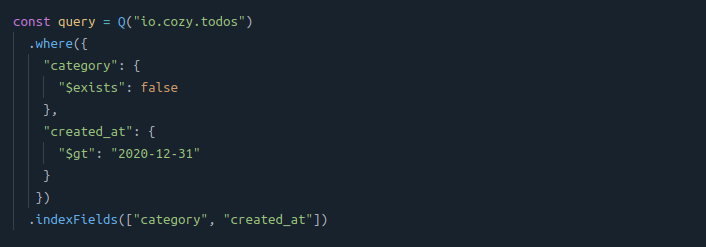
⚠️ This query will typically return nothing in CouchDB. This is because a document will be indexed only if the indexed fields exists in the document. So a task without a set category will never be indexed.
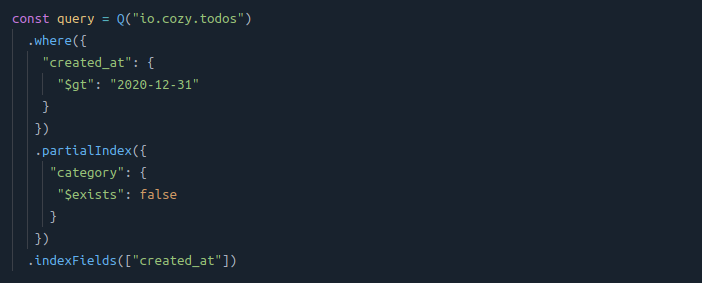
A partial index solves the issue, as it will simply evaluate the existence of the field on indexing time:
Queries with constant values
You might need to retrieve documents based on a field value that you know will never change. For instance, you might have a status field that is set to “ARCHIVED” when the task is archived.
To retrieve these tasks, you can directly use a partial index:
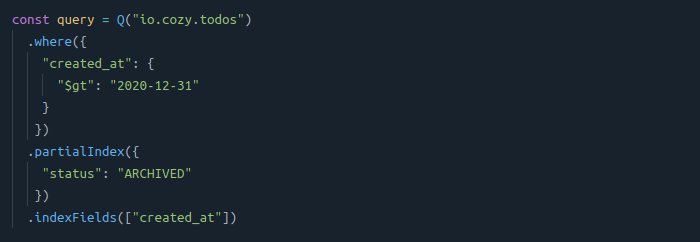
In this case, a partial index is useful to reduce the index size as you avoid to index the status field.
💡 Lightweight indexes take less space on disk and are more efficient both for lookups and updates, so this optimization could be worth it if you have a lot of data to handle.
💡 Partial indexes are useful to keep contiguous rows in indexes, to use existence predicates and to decrease indexes size. Depending on your use-cases and data volumetry, you could benefit a lot from partial indexes!
💡 In SQL, you can create partial index simply by specifying a WHERE clause in the index definition. See how to do it with PostgreSQL. In MongoDB, the principle and syntax is quite similar to CouchDB.
Cozy Contacts: a real-world use-case
Theory is great, but let us illustrate what we discussed by a concrete example and how the performances dramatically improved in our Contact application, thanks to partial indexes.
In Cozy, there are several ways to import contacts: you can typically import them directly from a vcard file or use the Google konnector to automatically synchronize contacts with your google account. And, because Cozy is an open-source platform, anyone can come up with a new way to import contacts, potentially with their own contact format.
Because of this, we implemented an asynchronous service that periodically checks when new contacts are added, and migrate them in the expected format for the Cozy Contacts app.
However, because this service is asynchronous, we cannot expect to have all contacts migrated when the user opens the application. So, we ended up with two queries run to retrieve contacts:
- A query to retrieve migrated contacts (
Q1) - A query to retrieve non-migrated contacts (
Q2)
Both those queries were checking the existence of a special document field for each contact to know if the contact is migrated or not. However, as we previously discussed, a missing field cannot be indexed in CouchDB. Therefore, Q2 was actually making a full-scan index to evaluate the non-existence of this field. As a result, this query was taking a lot of time to complete, as soon as the user had a lot of contacts.
And the worst part is that Q2 actually returns nothing most of the time, as the contacts are migrated only once!
So, Q2 was an excellent candidate for partial indexes: we implemented Q2.1 that finds contacts with the missing field through the partial index: this way, the document is still indexed when the field is not here. You can find its actual implementation here.
The diagram below show the performance impact by comparing the execution time of the three queries in the most common scenario: Q1 returns 1000 contacts while Q2 and Q2.1 returns nothing.
Q2 complexity is O(n) with n the total number of contacts, while both Q1 and Q2.1 are O(log n). Note Q2.1 does not even appear in the diagram because it only takes few ms to perform.
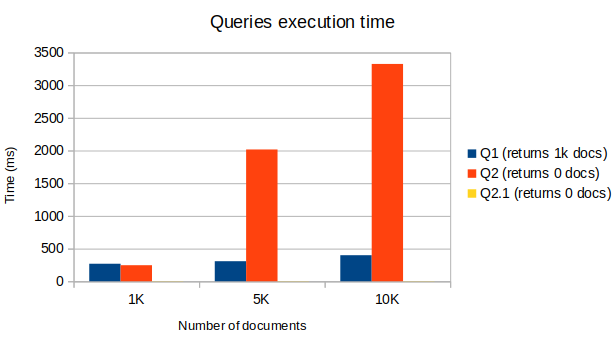
Finally, using a partial index improved the overall queries performances by a factor 2 for 1K contacts, and by a factor 8 for 10K contacts. Neat!
Conclusion
We hope this little index tour gave you some insights about performances and data indexing.
You can start how to learn developing a Cozy app here: https://docs.cozy.io/en/tutorials/app/
To learn more about how to manipulate data, you can reach here: https://docs.cozy.io/en/tutorials/data/
By the way, if you're located in France and you're interested about Cozy, we're hiring!



