

Cette question - brûlante - s’impose à nombre de services en lignes français et européens, publics et privés. Nous partageons ici notre analyse et des éléments de rationalisation.
Le problème
En 20 minutes le 10 mars dernier nous perdions 43 machines dans l'incendie du datacenter d'OVH à Strasbourg. Nos mécanismes de redondance et de bascule automatique ont bien fonctionné, nous n'avons pas perdu de donnée, ni fait subir d'interruption de service à nos utilisateurs.
En moins de 36h nous avions réinstallé, configuré et injecté de nouvelles machines pour reconstituer le niveau de redondance nominal de nos clusters, de façon à pouvoir être prêts à perdre à nouveau autant de machines.
Hourra ?
Bien sûr, Cozy ne peut que célébrer le travail de tous ceux qui ont contribué à ce sans faute !
Mais se sentir aujourd’hui invincible du fait de cette victoire serait la garantie de vivre une catastrophe lors du prochain incident. Il est donc essentiel de vouloir encore et toujours réduire le risque de devoir appliquer nos procédures exceptionnelles. Dit autrement, nous devons nous poser la question de savoir si cet incendie est le signe qu'OVH n'est pas assez fiable et que nous serions plus en sécurité ailleurs.
Le modèle low cost d’OVH entraine-t-il un niveau de service structurellement trop faible ?
Le niveau de service global d'OVH n’est pas le plus haut de gamme du marché. C’est entendu.
Notons tout d’abord que les défaillances sont régulières ; voici par exemple une liste de 7 incidents majeurs sur 2019 affectant des grands noms du numérique, comme Amazon Web Services, iCloud d’Apple ou encore Google Cloud.
D’autre part, en alpinisme, on aime dire que le pire danger est d'oublier le danger. Pour une infrastructure, c'est la même chose. Il ne faut jamais baisser la garde.
Maintenir cette forme de paranoïa à chaque geste sur un édifice aussi complexe qu'une infrastructure informatique est très difficile. Or le fait est que ces dernières années nous avons rencontré de nombreuses pannes ponctuelles.
Ces - petites - défaillances ponctuelles ont rodé nos procédures et paramétrages, nous ont fait adapter notre supervision, nous ont poussé à automatiser le service discovery et la configuration de TOUTES nos machines…
Quand nous perdons à nouveau un accès réseau ou une machine, nous plaisantons en nous demandant si un jour OVH ne va pas nous facturer son "Chaos Monkey" [1]
Paradoxalement, un fournisseur avec un plus haut niveau de service nous aurait sans doute fait un peu perdre de vue notre exposition au risque et aujourd’hui nous serions moins prêts.
Un accident, même majeur, n’est donc pas en soit suffisant pour tirer des conclusions, il faut pousser plus loin l’analyse.
Cozy serait-il atteint du syndrome de Stockholm ?!?
Sommes-nous comme ces otages qui, par des mécanismes d’identification et de survie, développent une empathie pour leurs geôliers ? Pour dépasser la discussion de comptoir, essayons de modéliser et quantifier le risque de perte de données du fait d’une perte d’infrastructure.
OVH existe depuis 21 ans et a opéré environ 170 années cumulées de datacenter (DC) avec un seul accident majeur détruisant toutes les machines d’un DC (dans la suite de cet article “Accident” sera relatif à une perte totale d’un DC).
Si l’espérance de vie d’un DC d’OVH était par exemple de 20 ans, alors OVH n’aurait eu que 0,016% de chance de ne pas avoir d’Accident pendant 170 ans. C’est à dire 1,6 chances sur 10.000.
N’avoir qu’un seul Accident sur cette période aurait relevé du miracle, on peut donc estimer que ce type d’accident survient en moyenne après plusieurs dizaines d’années.
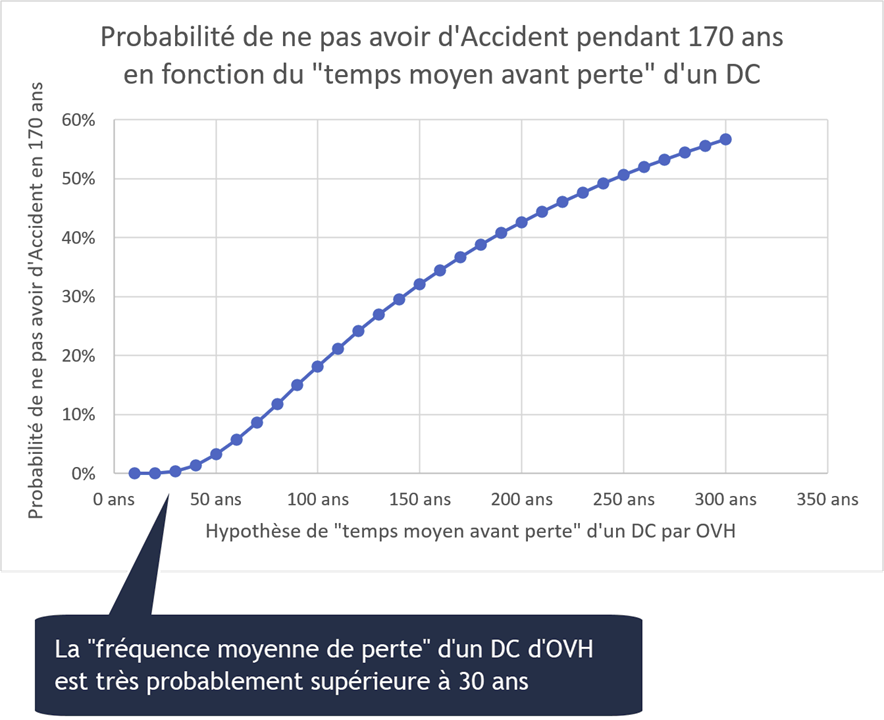
(voir les tableaux complets pour vérifier les calculs et jouer avec les chiffres [2])
A ce stade, la question est donc de savoir si la probabilité de perdre en moyenne tous les 30 à 200 ans un datacenter où seraient toutes vos données est un problème pour votre organisation..
Pour Cozy, ce niveau de risque n'est pas acceptable car les données de nos utilisateurs sont notre raison d’être et nous comptons bien vivre plus de 200 ans ! Nous avons donc :
- redondé astucieusement les données et services sur plusieurs datacenter,
- lesquels sont répartis sur plusieurs sites, dont les risques - incendie, inondation, panne électricité… - sont indépendants les uns des autres (une inondation touche rarement des sites distant de plus de 500km, idem panne de courant, vague de froid etc..)
Au final, la perte d’un datacenter complet est sans incidence pour Cozy.
Mais alors perdre 2 datacenters serait catastrophique pour Cozy ?
En effet. Peut on dès lors évaluer le risque de perdre 2 datacenters dans un intervalle de temps qui ne nous laisse pas le temps de reconstituer notre niveau de redondance nominal ?
Si on estime :
- que la durée moyenne après laquelle un datacenter d'OVH brule est de 30 à 200 ans,
- que cette durée moyenne est constante (on parle de taux de défaillance constant, approximation raisonnable à cette échelle de temps dont on peut considérer qu’elle lisse usure et travaux de maintenance)
- que le délai de reconstitution de notre niveau de redondance est de 5 jours (en l'occurence nous n’avons eu besoin que de 36h pour reconstituer les redondances essentielles perdues)
Sous ces hypothèses, il s'écoule en moyenne entre 65 000 ans et près de 3 millions d'années avant de perdre deux datacenter d'OVH à moins de 5 jours d'écart.

La perte d'un seul datacenter puis d'un disque dur supplémentaire suffit pour perdre des données, non ?
Dans le cas d’une simple duplication des données, perdre 2 datacenter fait perdre toutes les données. Mais après avoir perdu un datacenter, on commence à perdre des données dès la perte d'un disque dur sur le second datacenter. Or c’est bien la perte de la moindre donnée que l’on veut prévenir.
Les calculs, en fonction du “taux de panne” des datacenter d’OVH et du taux de panne moyen d’un disque dur, montrent qu’il faut en moyenne de 10 à 67 mille ans avant qu’un tel événement ne se produise (pour rappel Jésus Christ serait né il y a 2 000 ans… et Google moins de 25 ans).
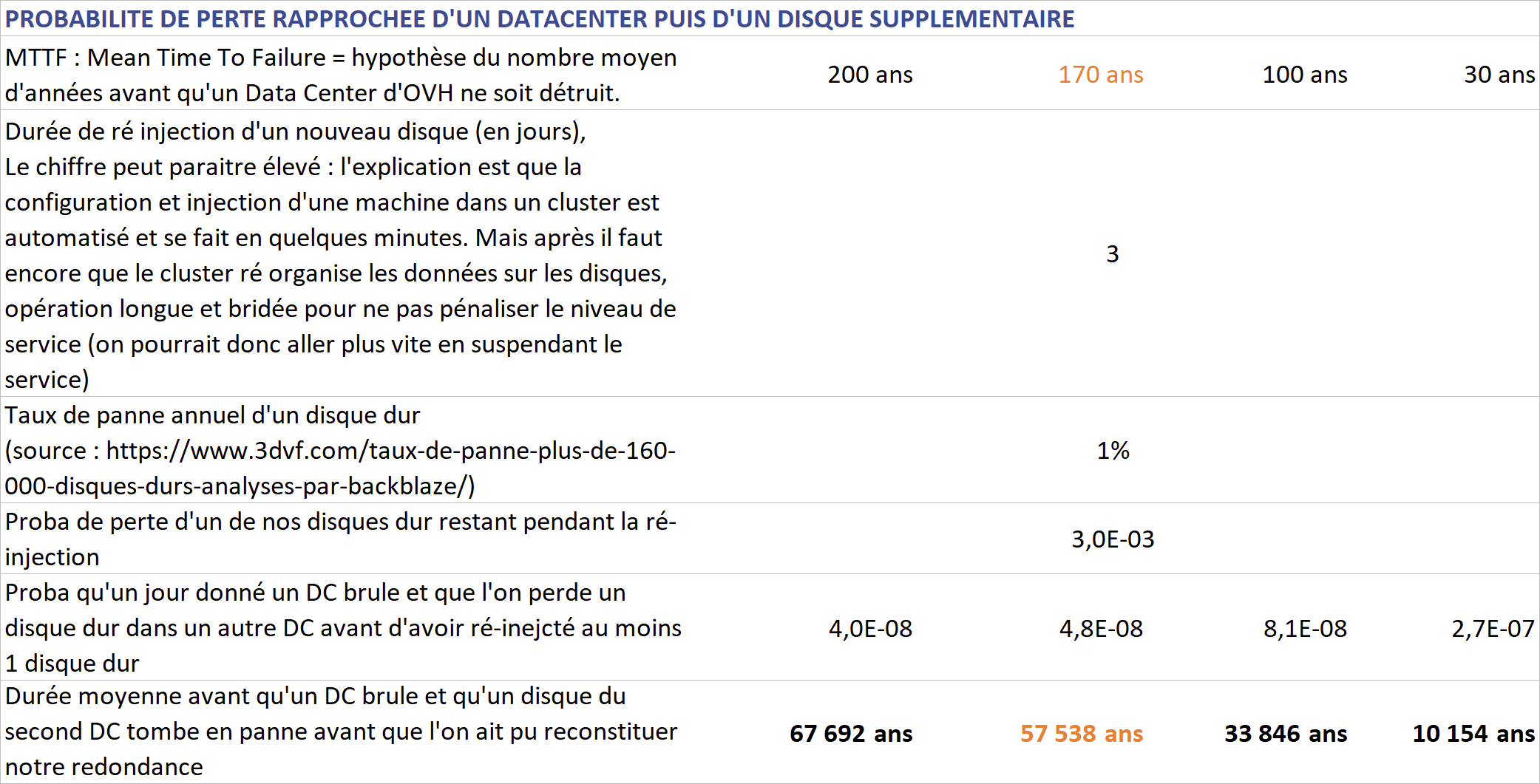
Ces calculs reposent sur des hypothèses difficiles à évaluer, donc il faut sécuriser, “quoi qu’il en coûte”
Nos hypothèses sont des approximations. Cependant, ce ne sont pas les valeur précises des résultats qu’il faut retenir, mais plutôt l’impact des différents leviers d’amélioration sur les ordres de grandeurs des risques pris.
En effet, nous ne voulons pas perdre la moindre donnée, mais comme la terre entière, nous disposons de ressources en quantité finies. Où donc mettre intelligemment notre énergie ?
Faut-il investir plutôt :
- sur des infrastructures avec des niveaux de services élevés
- ou bien sur les couches logicielles et procédures organisant redondance et résilience
Supposons qu’OVH fasse des investissements pour diviser par 10 le taux d’incendie de ses datacenters. Cela ferait passer la fréquence moyenne d’un accident majeur de quelques dizaines d’années, à quelques centaines d’années. Et ce à des coûts sans aucun doute exorbitants, l’industrie nucléaire est là pour nous rappeler que le zéro défaut est très cher, et jamais tout à fait atteint.
Alors que par la redondance des données, par exemple en doublant notre infrastructure comme dans le calcul précédent, la fréquence moyenne de survenue d’un tel Accident se compte à minima en dizaines de milliers d’années.
Sans compter que nous avons gardé le meilleur pour la fin : nous répartissons en fait les données sur non pas deux mais trois datacenters, ce qui fait que pour commencer à perdre des données il faudrait perdre complètement deux datacenters puis encore un disque dur, événement dont la fréquence moyenne va de 22 à 988 millions d’années…
La redondance et la distribution des données sont donc des leviers donnant accès à des ordre de grandeur de résilience qu’aucun dispositif physique ne pourra atteindre.
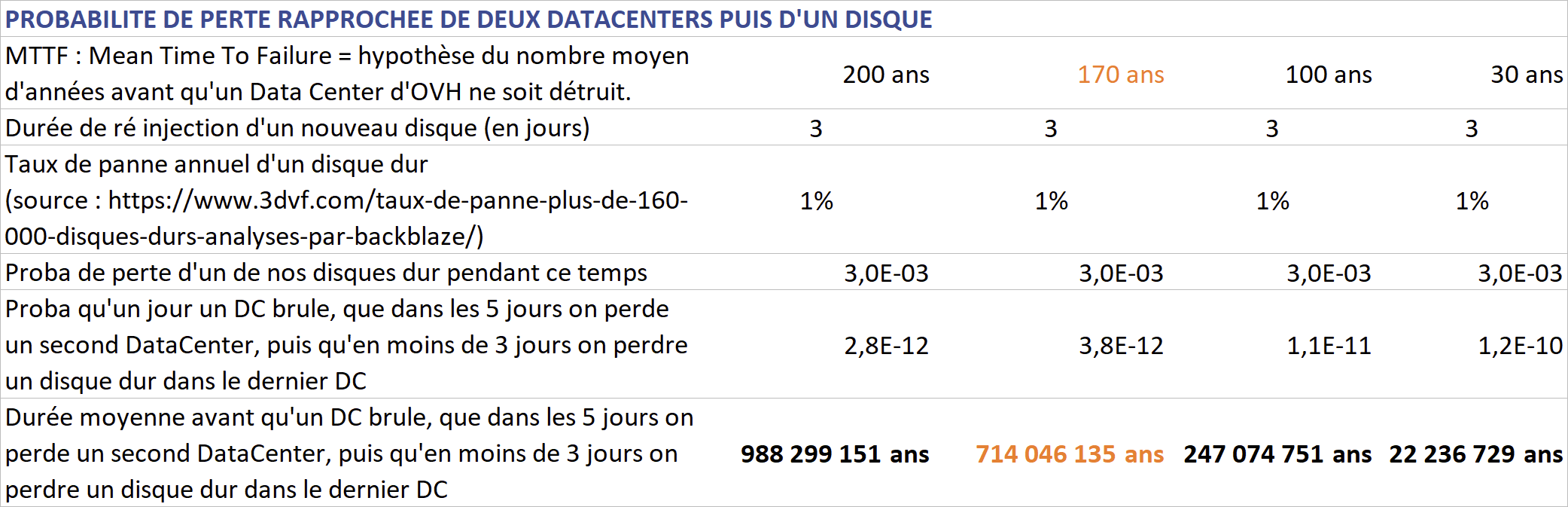
Mais pour arriver à ça vous triplez les données, c’est cher et mauvais pour l’environnement…
Prix : c’est précisément la raison pour laquelle il vaut mieux disposer d’une infrastructure à un prix compétitif et mettre en place une redondance répartie sur 2 voir 3 sites, plutôt que de rester sur un unique site avec une infrastructure plus fiable mais beaucoup plus chère.
Impact environnemental : bonne nouvelle, une répartition sur plus de 3 sites permettant de perdre 2 DC peut être faite de manière astucieuse pour que le taux de duplication ne soit pas de 3 mais de … 1,5 ! Comment ? Suspens… 🙂 Le surcout "environnemental" de cette sécurité n’est donc alors que de 50% du volume de donnée. Une telle optimisation requiert un dispositif technique complexe qui fait que l’empreinte écologique d’un service Cloud ainsi opéré, à même volume de donnée et niveau de sécurité, est plus faible que les solutions plus simples.
Investir dans le logiciel et la rigueur de l’automatisation est bien plus “rentable”, tant d’un point de vue financier qu’écologique.
Le prix est-il donc le seul critère pour choisir un hébergeur ?
Pour que la redondance puisse être mise en œuvre encore faut il :
- que le réseau soit fiable et supporte la surcharge de la bascule de tous les clients du DC perdu vers les autres DC
- que l’hébergeur dispose de suffisamment de DC contenant les types de machines dont vous avez besoin
- que les DC de l’hébergeur soit très indépendants les uns des autres pour que les risques soient découplés : si inondation de l’un, pas des autres, si panne de courant de l’un, pas des autres etc…
- que le temps de mise à disposition de nouvelles machines ou de remplacements de disques durs soit le plus court possible de façon à reconstituer rapidement le niveau de redondance adéquat
- que l’hébergeur dispose d’une capacité de communication de crise qui soit efficace
- disposer de la taille critique pour rendre les points précédents possibles
D’autres considérations plus stratégiques entrent également en ligne de compte :
- Est ce que l’hébergeur dépend d’une juridiction avec laquelle nous sommes confiants pour opérer notre service et tenir nos promesses ?
(pour Cozy Cloud cela veut dire être en France ou éventuellement en Europe) - Est ce que l’hébergeur participe à un écosystème économique vertueux pour notre propre business ?
Alors, faut-il quitter OVH ?
Nous préférons rationnellement investir sur la redondance et distribution des données plutôt que sur les niveaux de services unitaires des éléments d’infrastructure.
Pour cette stratégie, OVH dispose des bonnes caractéristiques techniques et commerciales :
- des tarifs compétitifs, notamment sur les serveurs physiques dédiés (souvent indispensables pour les gros clusters), et ce sans que les DC ne brulent tous les 10 ans
- une dizaine de sites en Europe, dont 3 en France (l’un des seul à le proposer), bien espacés
- un réseau d’interconnexion et de peering solide et performant, point fort historique d’OVH
- une maitrise de la chaine d’approvisionnement pour rapidement augmenter ses ressources (nouvelles machines)
- une communication de crise transparente, temps réel et précise (technique)
Sans compter qu’OVH est un “acteur local” :
- dont nous connaissons les équipes, les forces et faiblesses, avec qui nous interagissons facilement,
- qui participe à un écosystème numérique dont les cercles vertueux nous seront bénéfiques :
- impôts et emploi en France et Europe pour maintenir et développer la maitrise des techniques et compétences dont nous avons besoins
- perception valorisante d’une filière française d’excellence numérique
- volonté de fédérer et animer un écosystème français et européen
- une alimentation électrique "bas carbonne", au moins pour les DC en France
Pour toutes ces raisons, nous maintenons notre confiance en OVH qui parvient à mettre sur pied une offre au tarif compétitif disposant des caractèristiques techniques et du niveau de service adapté. Ce n’est pas un incendie qui nous fera changer d’avis 🙂
PS : notes sur le cadre de validité des calculs et estimations
Les calculs de probabilité réalisés ci dessus reposent sur des hypothèses et simplifications.
Nous n’entrons pas ici dans le détail précis de notre organisation de la redondance et de la répartition des données.
Nous n’envisageons pas ici tous les scénarios de perte de donnée pour nous concentrer sur le cas le plus radical, le cas de la perte intégrale d’un DC.
Par exemple dans le cas où vous triplez les données et les répartissez sur 3 DC, perdre intégralement 2 DC n’est pas un problème. Pour autant, perdre 3 disques durs, un sur chaque DC, peut “mal tomber” et entrainer la perte des fichiers dont les 3 copies étaient précisément sur ces 3 disques…
En fonction de la topologie de vos données une myriade d’autres cas sont possibles. Mais tous ont des probabilités d’occurrence qui diminuent très fortement avec une bonne organisation de la duplication et répartition des données.
Encore une fois, l’idée ici n’est pas de modéliser finement tous les risques d’une architecture donnée, mais bien de voir que les ordres de grandeur poussent à s’organiser de façon à ce qu’un accident comme celui qu’a connu OVH soit un événement “normal”.
D’autre part les causes de perte de données ne se limitent pas aux causes matérielles. Bugs, erreurs humaines, malveillances, sont autant d’autres enjeux que tout service en ligne se doit également d’adresser. Il est essentiel pour Cozy de rester humble face à toutes ces difficultés, loin de nous l’idée de donner des leçons, ce serait le meilleur moyen pour faire baisser notre niveau de vigilance…
Chaos Monkey est un logiciel en charge de provoquer des pannes aléatoires sur un environnement réel pour s'assurer que le système informatique continue néanmoins à fonctionner et détecter les améliorerations à apporter aux procedures de continuité de service. ↩︎
Vous pouvez télécharger la feuille de calcul contenant toutes les données et calculs au format Microsoft Excel ou au format OpenOffice Calc. ↩︎


