

Cet article est également disponible en version anglaise.
La crise sanitaire actuelle a montré combien il est essentiel de disposer de données afin de prendre des décisions politiques. Mais aussi combien certaines données sont sensibles, et ne devraient être manipulées qu’avec précaution. En témoignent les débats actuels en France autour de la pertinence du couvre-feu à 18h, du traçage des cas contact Covid et de la constitution d’une base de données médicales. Dans les trois cas, pour l’application TousAntiCovid comme pour le Health Data Hub, le choix de solutions qui centralisent les données soulève des questions, des inquiétudes. Ce modèle centralisateur, où toutes les données sont regroupées dans une base unique, n’est heureusement pas le seul possible. Il existe des alternatives, qui permettent d’analyser les données, d’en extraire des indicateurs pour orienter la recherche et les politiques publiques, tout en garantissant le sécurité et la confidentialité des données. Des solutions qui veillent à ce que les citoyens conservent le contrôle sur leurs informations personnelles, que celles-ci ne puissent être utilisées sans leur consentement.
Nous présentons ici une de ces solutions qui permet d’entraîner une IA avec les données de nombreux individus sans jamais les divulguer à des tiers, grâce à un protocole décentralisé.
Contre COVID : combien de temps maintenir fermés les salles de sport et autres lieux publics ?
Aujourd’hui, à l’heure où la France entière adopte de nouvelles mesures restrictives (couvre-feu généralisé à 18h), est-il encore légitime de se poser cette question ? La réponse est oui et elle se posera aussi à l’heure où le gouvernement lèvera ces restrictions :
- devrons-nous ouvrir les restaurants, les bars, les salles de sport, les piscines, les théâtres et autres lieux culturels ? Dans quel ordre ? Dans quelles conditions ?
- nos enfants devront-ils encore porter un masque dès 6 ans ?
- devrons-nous laisser confiner les personnelles les plus fragiles ?
- devrons-nous fermer les cantines des écoles ? les crèches ? ré-ouvrir les universités ?
Une chose est certaine : une épidémie porte sur des échelles très grandes, et se comporte différemment selon de nombreux critères, notamment temporels et spatiaux, ce qui complexifie l’isolement de variables pertinentes.
Chez Cozy Cloud, nous apportons une approche innovante et tenterons de répondre à cette première question comme cas d’application : est-ce que fermer les salles de sport contribue à entraver le virus ?

Aujourd’hui, répondre à une telle question comme aux autres questions avancées précédemment requiert de centraliser les données de toute une population.
En effet, cela reviendrait à étudier des corrélations entre un grand nombre de données personnelles et mutualisées d'une population :
- fréquence de fréquentation de la salle
- antécédents médicaux
- âge
- autres activités sportives pratiquées
- etc
Pour analyser ces données, l’état de l’art - c’est à dire les connaissances actuelles - porte traditionnellement sur des méthodes exigeant de faire les calculs sur un serveur qui centralise toutes les données nécessaires et pertinentes d'une population.
Deux obstacles majeurs émergent :
- comment récupérer toutes ces données éparpillées et diverses ?
Les données d’une population sont éparpillées et les approches centralisées actuelles ne peuvent pas faire fusionner tous les silos des services existants ce qui nous obligerait à lancer des partenariats avec Google Maps, Withings, l’Assistance Publique - Hôpitaux de Paris (APHP) et tous les autres hôpitaux régionaux, le Health Data Hub (HDH). Autant d’acteurs français qu’américains rendraient le cadre légal nébuleux compte tenu de législations différentes.
- comment ne pas permettre des utilisations détournées de ces données ?
Aujourd’hui, anonymiser des données aussi diverses est mathématiquement impossible sans dégrader la valeur utile des données.
Approche décentralisée du cloud personnel
Cette complexité dans la mutualisation des données pour répondre à une telle étude avait été anticipée chez Cozy Cloud avant même le contexte sanitaire que nous connaissons actuellement. Avec un train d'avance, nous lancions en 2018 Cozy, cloud personnel français et open source - plateforme de données personnelles dans laquelle l’individu réunit toutes ses données pour en avoir à la fois plus de contrôle et plus d’usages. En émergeait alors un étonnant paradigme où l’individu peut ainsi bénéficier de services mobilisant toutes ses données, toute son intimité numériques, sans qu’aucune donnée ne sorte de chez lui.
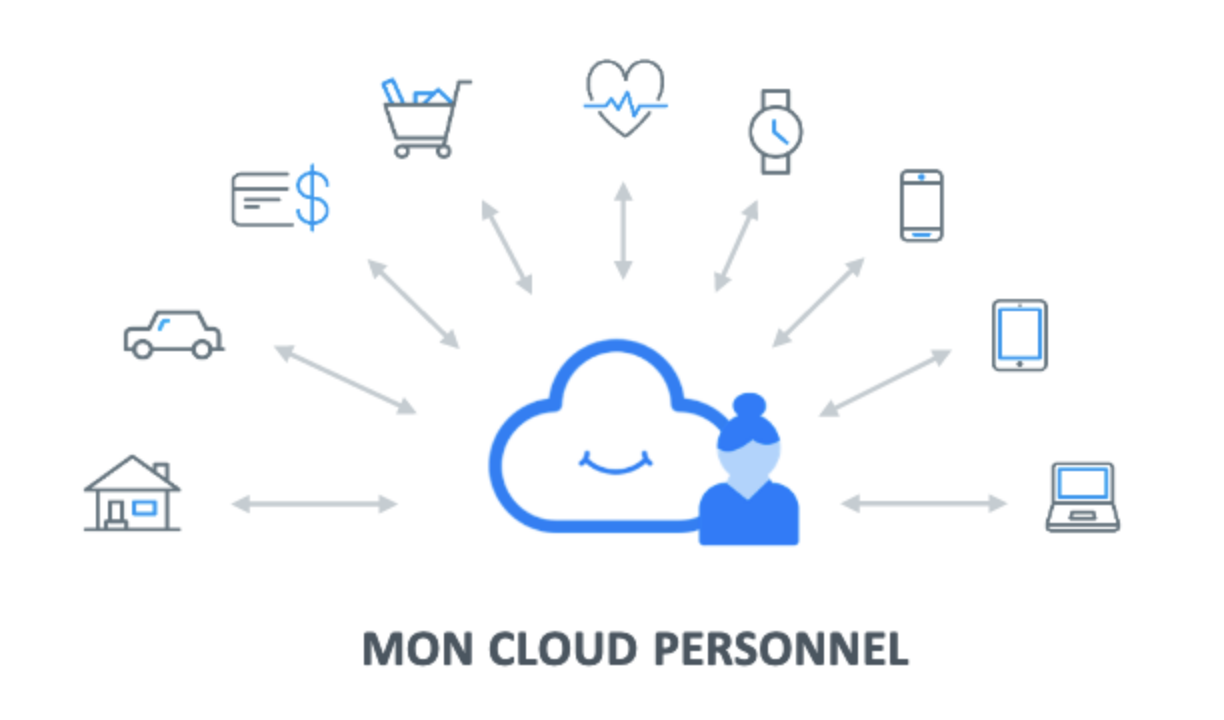
C’est cette ambition de permettre une décentralisation à l’échelle de l’individu en lui mettant à disposition un cloud personnel qui constitue une approche différente et innovante pouvant répondre à la question posée.
“Qui est légitime pour réunir et contrôler toutes vos données personnelles ? Quelles sont les conditions à réunir pour que le numérique soit structurellement au service de la démocratie ?”
Cloud personnel : une approche innovante et différente de l’approche centralisée des GAFA qui embarque l’utilisateur
L'idée de Cozy Cloud est d'équiper les individus d’un cloud personnel, domicile numérique qui réunit toutes ses données personnelles car l'individu est le seul légitime pour accéder à toutes ses données.
Appliqué à l’exemple de la fermeture des salles de sport, avec son cloud personnel Cozy, l’individu peut ainsi :
- récupérer automatiquement dans son cloud personnel les données de géolocalisation de son smartphone qui indique la fréquentation précise de sa salle de sport, ses antécédents et constantes de santé provenant de son Espace Numérique de Santé, de son tensiomètre connecté à Withings, de son service de télésurveillance de son diabète proposé par l'APHP, etc.
- contribuer à un programme d'apprentissage décentralisé lui garantissant que ses données ne sortent pas de son cloud personnel.
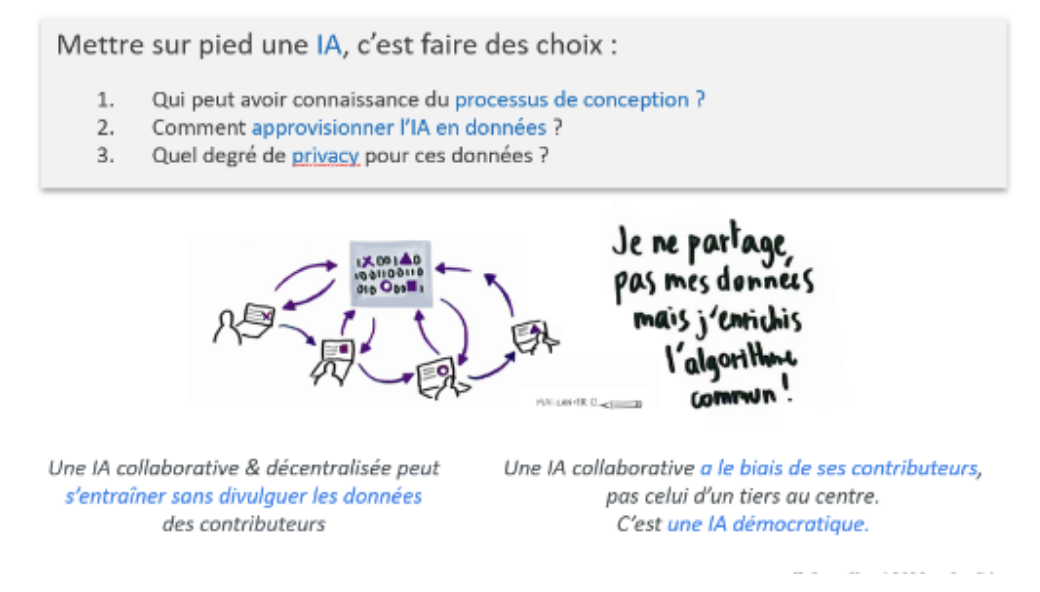
Cozy ouvre ainsi la voie à une intelligence artificielle décentralisée où l’IA peut apprendre des données de tout le monde sans que quiconque ne partage ses données.
DISPERS : Protocole décentralisé activable
DISPERS : un protocole décentralisé
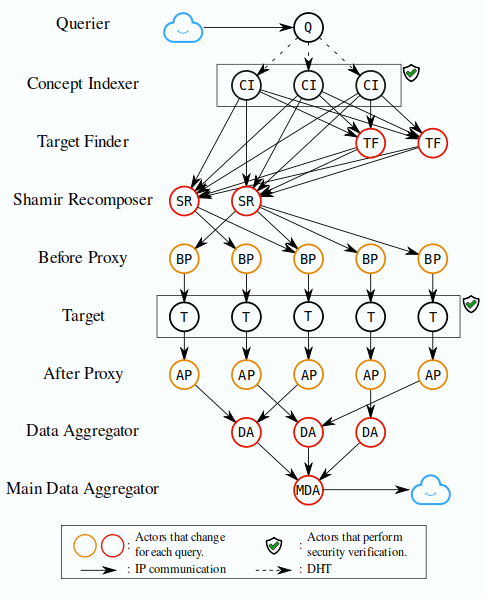
Comme évoqué précédemment, le cloud personnel respectueux de la vie privée fournit à ses utilisateurs un espace numérique dédié et sous leur seul contrôle. Cependant, cette plateforme reste mono-utilisateur et, sans un cadre adéquat, ne permet pas de créer des applications multi-utilisateurs offrant les mêmes garanties. L’objectif du protocole DISPERS publié avec INRIA, était donc de définir ce cadre pour permettre, plus spécifiquement, l’exécution de requêtes distribuées respectueuses de la vie privée sur un ensemble de cloud personnel. Dans notre contexte, on considère que chaque individu de la population étudiée dispose de son cloud personnel.
Ce protocole est issu d’une thèse CIFRE entre Cozy Cloud et l’équipe PETRUS d’INRIA Saclay. Plus qu’une méthode d’anonymisation, ce protocole apporte des garanties fortes qu’un calcul portant sur des données personnelles ne dévoilera aucune information utile tout au long de son exécution, et ce, même en présence d’acteurs malveillants. Ces travaux ont donné lieu à articles publiés dans de grandes conférences académiques internationales :
- Julien Loudet, Luc Bouganim, Iulian Sandu Popa Privacy-Preserving Queries on Highly Distributed Personal Data Management Systems
- Julien Loudet, Iulian Sandu Popa, Luc Bouganim SEP2P: Secure and Efficient P2P Personal Data Processing
Le protocole DISPERS s’intègre également dans le projet ANR PerSoCloud, une coopération entre Cozy Cloud, Orange, INRIA Saclay et l'Université de Versailles Saint-Quentin-en-Yvelines, qui a pour objectif de faciliter la mise en relation du domicile numérique personnel de chacun.
DISPERS propose ainsi une manière de distribuer les tâches et informations entre plusieurs clouds personnels Cozy. Le protocole incorpore des procédés pour cacher les détenteurs de l’information ou rendre les données incompréhensibles par l’acteur qui sera responsable d’une sous-tâche. Ainsi, aucun acteur isolé n’est en mesure de compromettre l’ensemble du calcul, ni d’accéder à des informations utiles !
Un enabler technologique développé avec INRIA
Les données étant déjà présentes dans les cloud personnels des utilisateurs, le protocole DISPERS peut se faire sans avoir à convaincre Withings, l'APHP et Google Maps de partager les données de leurs utilisateurs ou trouver le cadre légal dans lequel contractualiser un tel dispositif. Les contraintes légales sont d’ailleurs une inconnue qui mériterait une attention particulière dans le cadre d’un protocole décentralisé : il faudrait lister les contraintes légales de chaque acteur participant au protocole.
Notre protocole permet à une étude épidémiologique de mobiliser les données, réunies sans difficultés par l'individu - dans notre cas utilisateur du cloud personnel Cozy, ce qui constituerait un cauchemar à un laboratoire d’études de récupérer la totalité des informations personnelles et consentements. Cela permet ainsi d’établir un calcul de corrélation et évaluer la prévalence du virus au sein de la population en fonction de son comportement, et ce tout en garantissant à l'utilisateur qu'il est techniquement impossible que les données utilisées ne sortent de son cloud personnel. Les données ainsi mutualisées sont impossibles à réunir aujourd’hui pour faire croître un bien commun.
Une nouvelle thèse sur les bases de DISPERS avec un focus sur l’IA
En complément de la précédente thèse portée par Julien Loudet, nous ouvrons une nouvelle voie avec une nouvelle thèse avec INRIA portée par Julien Mirval et Cozy Cloud qui vise à pouvoir faire de l’apprentissage distribué dans un contexte IA.
Cas d’application : pertinence de la fermeture des salles de sport pendant l’épidémie du COVID-19 ?
Conditions d’application
À supposer que la population de notre échantillon dispose d’un cloud personnel dans lequel chaque individu a connecté son compte Withings et récupéré ses données GPS (dont celles de fréquentation de sa salle de sport) ainsi ses données de santé récupérées par son Dossier Médical Partagé (DMP) (testé positif ou non au COVID).
Déroulement de l’étude
À partir de ces données, et en appliquant le protocole DISPERS :
- on peut alors regarder le pourcentage de contamination de ces individus avant et après la fermeture des salles de sport
- on peut le comparer avec le pourcentage de contamination des personnes dites équivalentes qui ne fréquentent pas la salle de sport (équivalent sur certaines variables pertinentes comme la localisation, l’âge etc.)
Résultats de l’étude
Si on voit une baisse dans le pourcentage de contamination avant et après la fermeture chez les individus qui y allaient ET que le pourcentage de contamination des individus qui n’y allaient pas ne suit pas la même tendance, alors on peut supposer qu’il y a un impact.
À noter que l'expérience ne prouve pas la causalité, mais permet d'établir des indices, qui additionnés avec d'autres études et/ou protocoles, permettrait de mieux cerner le comportement de l'épidémie.
Conclusion
Le machine learning décentralisé en tant que nouvelle modalité de mutualisation des données ouvre la voie d’une IA démocratique. Une telle IA a besoin d’apprendre sur un jeu de données vaste et transverse provenant de multiples sources, tout en respectant la vie privée des utilisateurs, ce que ne permet pas les approches centralisées actuelles qui fonctionnent en silos. Dans une société démocratique, les individus eux-mêmes contrôlent leurs données.
En adoptant un cloud personnel pour vous réapproprier vos données personnelles, votre IA Personnelle permet un accès à votre “intimité numérique complète” sans jamais la divulguer. Un changement de paradigme nécessaire, alors que les risques d’atteintes à la vie privée n’ont jamais semblé aussi forts que dans cette période incertaine.
Ressources et articles
- Ethique de l'Intelligence Artificielle - Etude réalisée par Cap Gemini - Juillet 2019
- Privacy-Preserving Queries on Highly Distributed Personal Data Management Systems - Julien Loudet, Luc Bouganim, Iulian Sandu Popa
- SEP2P: Secure and Efficient P2P Personal Data Processing - Julien Loudet, Iulian Sandu Popa, Luc Bouganim
- Article Entrainer une IA sans posséder la donnée est possible - Martin Masson


